
System programming is still essential, but it seems to be much harder than application programming. Why is that and how to overcome this – these are the questions I’ll try to find answers for in this article.
Table of Contents
Introduction ¶
A hundred years ago, a person could not imagine to be able to play any musical instrument they want, to create new interactive worlds, or to launch cars into space. Life was simply not enough.
Then the machines came. Silicon computations allowed us, mere mortals, prolong our lives virtually and literally.
Music creation software, game development engines, 2D and 3D editors, neural networks, AI and machine learning, motion capturing, navigation, medicine, wearable devices, smartphones… Thanks to these, a person now can do a lot of things while having more free time during their lifespan.
It all happened because a human learned to communicate with machines with means of programming languages. Early inventors of the future were brilliant people able to coin fundamentally new concepts which last until today.
But this is the how the humanity evolves: we accumulate knowledge and pack, shortcut it. We don’t need to keep in head proofs of every mathematical theorem, and we don’t need to fully understand the nature of an axiom. Instead, we store theorem and axiom statements. With that in mind, we have more space to solve new problems.
The same applies to programming. Those brilliant people inevitably become old, as real system programming knowledge fades away. On the surface, the amount of those who really understand how machines work seems to shrink.
Also this. My aim is to bring ’96 back for ‘20s devs pic.twitter.com/avFQxxIfpP
— Vlad Faust (@vladfaust) May 23, 2020
“But I can run a newural network with Python!”, one would argue. Well, who do you think develops TensorFlow itself? TensorFlow isn’t written in Python, kid.
Writing a game in Lua or Ruby is totally possible, as well as creating a messenger or code editor in Electron. However, Electron, as any mature game engines, are still written in C++.
Almost any meaningful software which needs to utilize a machine with more than 20% efficiency, is written in a system programming language.
System programming is the foundation of the development of the human civilization.
Regardless of its importance, system programming seems to be less popular than application programming, because it’s known to be harder to both learn and master. It is definitely easier to spin up a web server, connect it to a database, set up some Stripe integration, drink a smoothie and proudly call yourself an entrepreneur.
But that does not invest in the human civilization’s progress on the Kardashov’s scale. The humanity will still depend on system programming in the foreseeable future. And we need new, fresh blood there.
In this article, I’ll try to take a peek on the current state of the system programming, find out why it’s not that popular and choose the best system programming language for the Next Big But Fairly-Low-Level Project ™.
Choosing the Right Language ¶
When choosing a serious language for serious system programming, the choice is broad: it’s either C, C++, Rust, or one of the many new LLVM-based projects.
C ¶
C is excellent at its simplicity, but bigger projects require higher-level language features, such as memory control, object hierarchy, lambdas etc.; therefore, C is out of competition here.
Ditto applies to C “replacements”, such as Ẕ̴̰̥̔͝i̷̥̣̍̓̉ġ̷̢̪͌̾́ and Patreon-lang.
C++ ¶
C++ is the grandfather of higher-level system programming.
It offers powerful features with a grain of Unix epoch practices and a great amount of undefined behaviour. Funnily enough, an experienced C++ programmer shall aware of not what C++ is, but of what it is not, i.e. undefined behaviour of the language.
That said, developing on C++ is pain, and it is easy to shoot your lower parts off by, say, returning a lambda with a closured local variable. Of course, it is possible to have a fancy third-party UB checking tool, but such a tool would never be perfect considering the amount of UB in the language itself.

Another Unix anachronism C++ inherits is the backwards compatibility with a bitter taste of Postel’s law: “most compilers implement that feature in different ways, let’s put it into the language after a short thought with design averaging from existing implementations!”. One may argue that backwards compatibility is a good thing, but let me postpone this discussion for a later section of this article.
Rust, pt. 1 ¶
Rust is a fairly young programming language with a reputable mission: empower everyone to build reliable and efficient software. Let’s deconstruct the statement.
One of the game-changing features of Rust is the separation between safe and unsafe code.
The ability to isolate volatile code worths a lot: if anything goes wrong, then you simply grep your codebase with unsafe filter and voilà – all the dangerous invocations are at your hand sight.
It also allows the implementation to perform crazy optimizations, say, by entirely removing parts of code; and it’s fine because there is no unsafe access to that code.
As a result, focusing on volatile code becomes easier, and nasty bugs are squashed faster.
Otherwise, the Rust compiler would yell at you, pointing at your mistakes in the safe code area. And those yells are detailed enough, so most of the time you have a clear picture on why you’re wrong and what to do with that.
Compared to C++, Rust compilation process is much friendlier and catches more bugs before you face them in runtime.

Another good thing about Rust is macros. Well, what’s good is the idea of macros; the implementation of macros in Rust is um… questionable. Nevertheless, macros allow writing code in code with much greater flexibility than with C++ preprocessor and constant expressions. Nuff said, macros are must-have in modern languages.
The built-in crates system Rust has brings powerful abstractions into the ecosystem. Those folks enjoying lower-level programming and having enough skills to do so can wrap unsafe, but performant code, into simple, but safe abstractions. And those who have a need to just make things work, may (comparably) easy adopt those crates.
Rust really does allow to build reliable (no undefined behaviour in-the-wild) and efficient (thanks to the zero-cost philosophy) software to everyone (with powerful abstractions).
But, there are always some “butts”.
First of all, only a few may say Rust has friendly syntax.
In the maniacal pursuit for the absolute memory safety, the language introduces plethora of abstractions such as borrow checker, six string types (hey, we’re making a language here, not a guitar), Mut, Box, Arc, Trait, requiring to do those ubiquitous unwrap(), as_ref() and borrow() (often chained) literally before every access.
Some may call it “hipster thinking”, but those small spikes like mandatory semicolons*, curly brackets wrapping, and otherwise unintuitive design decisions like constantly “screaming code” with ubiquitous bangs (!) and overloaded documentation semantics — they make writing and reading Rust code harder.
Definitely harder than Ruby or, say,
J̸̧̨̹͈̦̏̅͒̈́͂͐̄̾͟͟ͅȃ̡͎̯̟̦͉͂͊̿̈́v̢̡͖͍̻̳̞͌͌̈̋̐͌̆͜a̴͖̱̟̩̹̘̺͊̃̋̇̾̀̀͐̊͐ͅS̶͚̣̥͚͈̥̤͔̾̎̎̿̔͊̋̉̓c̶̡̧̗̻̊̈̋̍̔̂̅̓̚͘͢ŗ̰͖̲̙͖͕̂̏̍͑̊̋ḯ̸̛̤̦̠͈̩̙̯̘̥̖̅́̊̀͑̕͠͠p̸̨̧̨̧̡̛̮̯͖̹͈̉̑̿͛̎̀͌̾͞ț̸̩͕͈̊͐̏̏̕͡ͅ
.
* In fact, semicolons are not mandatory everywhere , which brings even more confusion.
From StackOverflow:
Semicolons are generally not optional, but there are a few situations where they are. Namely after control expressions like
for,if/else,match, etc.
A wise man once said:
The complexity of a language feature is proportional to the number of articles explaining the feature.
Here go a tiny fraction of reads on why Rust is not even nearly to an intuitive language:
-
Understanding lifetimes (the subreddit itself is straight proof of how insanely complex the language is)
-
Understand smart pointers in Rust (the StackOverflow tag is full of that gold)
The following is my personal collection of “why I love Rust”.
⚠️ Lots of nasty tweets inside
The learning curve of @rustlang for whoever is used to GC languages is steep but very interesting. Like, this code does *not* compile in Rust, but it actually makes a lot of sense 🤯:#programming pic.twitter.com/yLru0bQ0gV
— Rémi Sormain (@RSormain) July 26, 2020
A nasty compiler error to start the morning. (pages of this) pic.twitter.com/vvMqcOsYcC
— Luca Palmieri 🦊 (@algo_luca) July 25, 2020
This is fine, just a perfectly normal function signature. pic.twitter.com/qotj5f3ndb
— Bodil Stokke, Esq. (@bodil) May 9, 2020
What is this even.https://t.co/0oUvVMJYEC
— James Munns (@bitshiftmask) February 11, 2020
when my backend looks like this so her frontend can look like that pic.twitter.com/xV4d6bi7ge
— Yaah 🦀 (@yaahc_) August 12, 2020
Methods with a variable number of parameters in @rustlang.
— Luca Palmieri 🦊 (@algo_luca) August 21, 2020
AMA.
😭 pic.twitter.com/IJ77fMLGPp
What is the correct @rustlang borrowing trait to impl for a wrapper type that enforces an invariant (i.e. NonZero*) but where otherwise you want it to be usable anywhere the inner type is usable? (note: poll, not quiz)
— Tony “Abolish (Pol)ICE” Arcieri 🦀 (@bascule) August 27, 2020
And sorry for these (you can open them in a new tab to enlarge (but please don’t)).
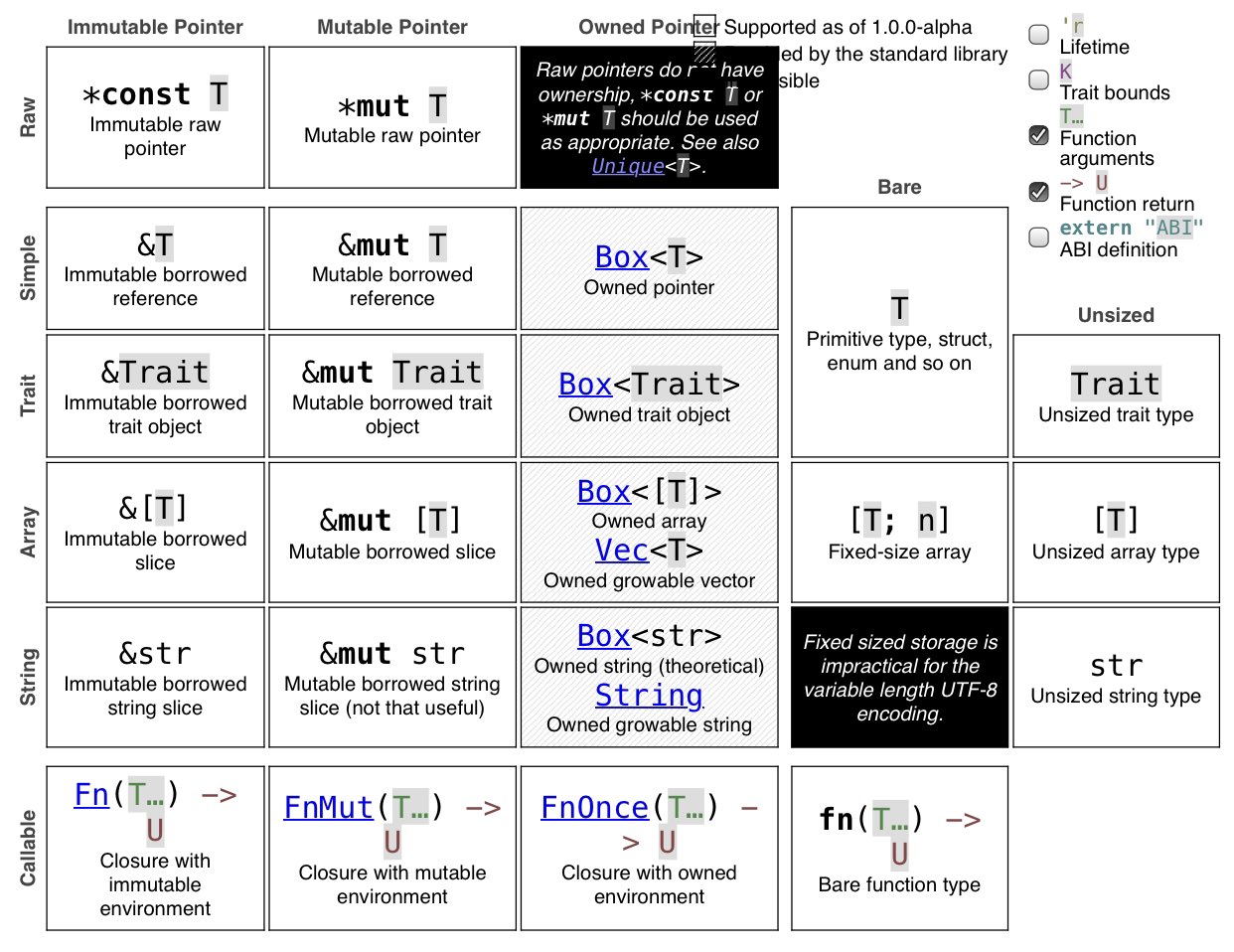

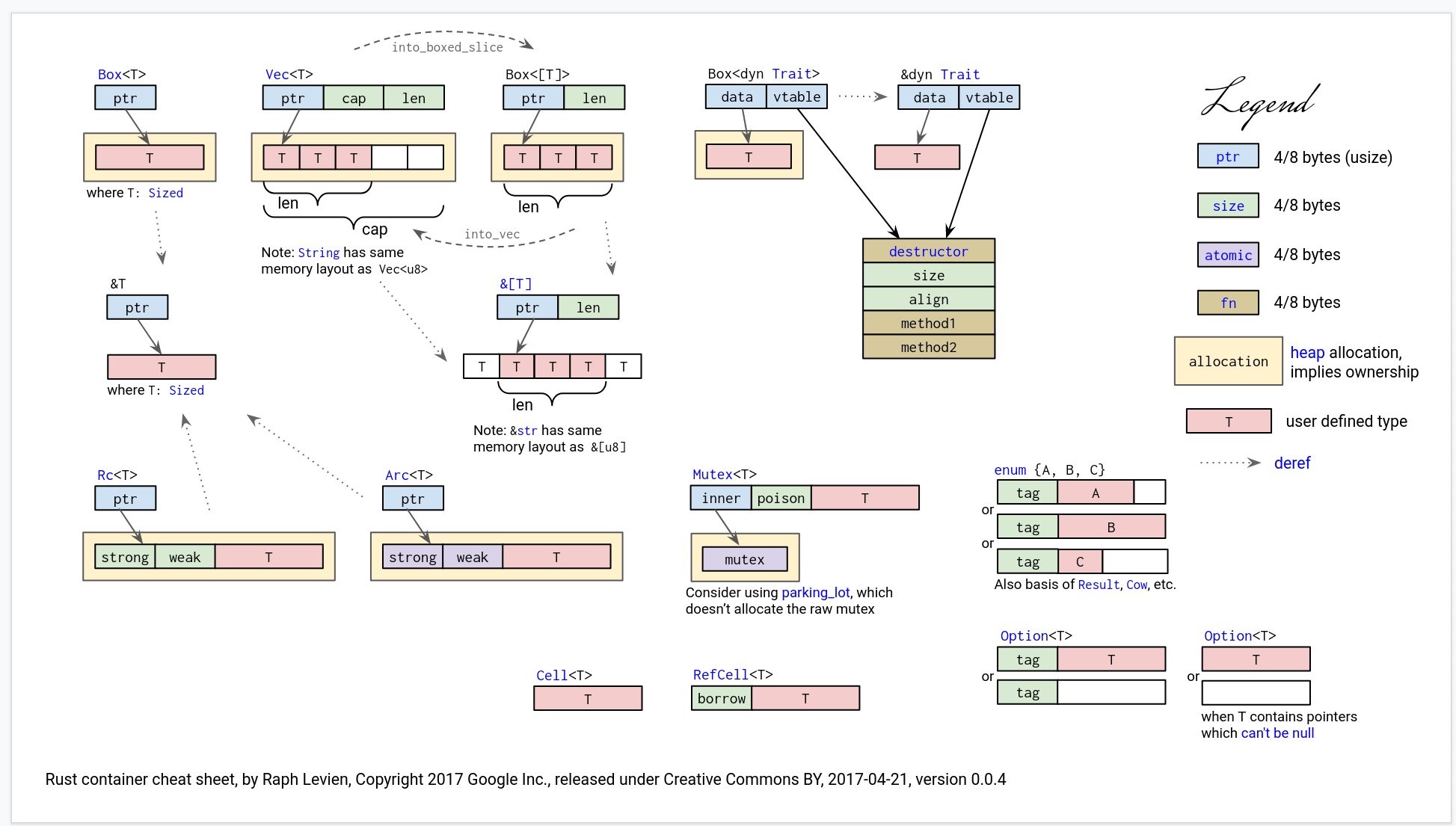
Rust is more confusing than C++, change my mind. On the one side, the compiler is always watching your moves, and it is responsible for ensuring protection from undefined behaviour… But that power comes at the price of unfriendly, clumsy, cumbersome syntax with lots of unintuitive abstractions and repetitive actions. Now, instead of keeping in mind of where C++ might blow, one shall be aware all the abstractions Rust brings in to choose the right one, and where to place a semicolon.
That said, the “for everyone” clause in the mission statement seems unfair to me now. It takes great effort to become fluent in Rust.
Regarding other two clauses in the Rust’s mission, I still have no claims on them.
Rust programs are known to be reasonably performant (if you ever manage to wait until rustc compiles with optimizations turned on), and there is even the academia-grade RustBelt organization ensuring the UB-safety.
You can always find more on what’s the good, the bad and the ugly about Rust, but the main point is that the language is not ideal, and there is definitely room for improvements. Plus one point to the justifying.
Challengers Worth Mentioning ¶
There are some other noteworthy languages, which nevertheless do not fit my requirements for various reasons.
Julia ¶
Julia is quite a mature language focused on scientific research.
First of all, I’m interested in a general-purpose language. I want to be able to create mainstream GUI applications, microservices and 3D engines, while Julia is focused on multi-dimensional arrays and plots.
Second of all,

You can find more on why not Julia here, with critique addressed here.
Check out another hilarious post on this matter. I personally love this quote:
Get a job! Then paint your masterpiece.
Telling that to a scientific language developed in MIT by scientists… Well, more on that later.
Nim ¶
Nim claims that it is a system programming language, but it currently lacks support for some lower-level features like alignment and address spacing. One still has to wrap a C/C++ library or write inline C/C++ for low-level programming, e.g. on a GPU. In that sense, Nim is similar to Python and other higher-level languages with FFI.
In addition to that,
-
Nim lacks proper object-oriented features like interfaces and mixins. OOP is crucial for a big project, change my mind.
-
Nim has Python-like indentation-based syntax with lines ending in
=and:, which is subjectively worse than Ruby-like syntax. Also theimportsemantic inherited from Python is fundamentally different from Ruby’srequire, and all the macros and generics semantics to be proposed becomes cumbersome to use withimports.
Crystal ¶
I love the core idea behind Crystal. I don’t like its implementation.
They are saying that Crystal is a general-purpose programming language, but that’s not true.
The language and its core team are focused on their needs, which is solely an amd64-linux platform.
The standard library is bloated with heavy dependencies like libxml and libyaml, the language itself has GC, event loop and unwinding-based exceptions (i.e. a runtime) built-in, and it’s therefore hardly possible to ship an executable for purposes other than serving requests over HTTP.
After almost 10 years in development, the core team still has disagreements in the fundamental design, and you may commonly see controversial claims by its officials regarding Crystal’s future on the forum. They even can not decide if Crystal is a compiled Ruby or something else.
Regarding the number of bugs the only implementation has… Once you dig a little bit deeper, it all begins to explode. Macros, generics, unions, interoperability: it may blow up anywhere. A core team representative without “core team” badge will then appear telling you that it’s not a bug, or wait, it is a bug, but it can not be fixed, oh wait, it can be fixed, but it’s not a bug, issue closed, thanks.
The recently introduced multi-threading brings even more problems due to the lack of proper addressing of the data races in the language. As most of the other design decisions in Crystal, this one has been taken somewhere in Manas without any open discussion.
I’ve spent two years in the Crystal ecosystem, and it did not move forward a bit, only backwards (bye, Serdar, bye Julien). A brilliant idea is buried by lack of focusing on the community needs. A hard lesson to learn. It’s time for (spoiler alert) Crystal done right.
Backwards Compatibility ¶
One would now jump into proudly announcing another language they’ve come up with, a utopia-grade solution to replace both C++ and Rust once and forever.
But the “forever” claim is kinda sloppy.
Remember how I mentioned earlier that backwards compatibility is not that good? The truth is that there will always be unforeseeable new features at some point, which have to be implemented, so a language stays competitive. For example, coroutines, a term coined in 1958, were not much of interest until 2010’s…
A product aiming to preserve backwards compatibility has to somehow insert new features into existing rules without introducing breaking changes.
C++ is an excellent primer on how not to.
Constrained by existing implementations, they add overly complicated co_await functionality into the standard library with extra garbage, which instead should have been built into the language itself (the functionality, not the garbage).
Another ad-hoc example is C++20 concepts.
Instead of allowing to restrict generic arguments in-place, a new requires syntax is added, which is quite cumbersome: see this and this.
As the hardware evolves, new fundamental types come into play. What’s the state of support of SIMD vectors, tensors or half-precision floats in C++? Brain floats? Oh please. Instead of being incorporated into the standard, implementations come with their own solutions, which further invests into the chaos.
But breaking changes are always painful, you would argue because on one side you want to use all the shiny new features, but on the other, you don’t want to spend a dime rewriting your code. It becomes even worse when an open-source library author you’re depending on decides that they will not support the older major version of a language; or, instead, they won’t move on to the newer version.
Given the number of open-source libraries your project depends on, you are in trouble, as library versions become stale or incompatible.
All that’s left is to visit a library’s bug tracker and leave a “what’s the status of this?” or “+1” comment, or maybe even put a little bit more effort:

When deciding on which language to build your next big project™ in, what you (or your PM) really want is that it accounts for all the present and future software and hardware features, has ultimate performance, maintainability, and never introduces any breaking changes, so you constantly reap the rich choice of forever-actual libraries.
Of course, such a language should be free as beer, as all of the forever-actual libraries. What’s the point otherwise?
Rust, pt. 2 ¶
Looks like Rust is the perfect candidate.
In the famous Rust: A Language for the Next 40 Years talk, they say that Rust will never have a major breaking change, staying young version ~> 1 forever, but still evolving.
Wait a minute.
At 32:15, Carol says:
When I first heard of that idea, I thought it sounds terrible from the compiler maintenance point of view: you have to maintain two ways to use every feature forever because we wanted to commit to all editions being supported forever. But it’s actually not that bad.
Then they take a good thinking sip of water and prove that it is indeed that bad.

Effectively, the “forever ~> 1” policy limits the number of fundamental features Rust MIR can have changed.
According to the talk, only a few keywords are to differ between editions.
So what we have in the dry run is a never-really-changing language with some slightly-different dialects to support. Occasionally, an implementation would opt-out of supporting an edition, and consequently all the libraries written in this edition become unusable. No ecosystem split, huh?
The editions problem could be addressed by supporting multiple editions in a single library. But what if a library author you’re depending on decides that they will not support a specific edition… Um.
Yes, we’re back to breaking changes and supporting multiple incompatible major versions editions of a language.
Oh those lazy open-source, free, OSI-licensed library maintainer bastards, they are the evil root of all the problems!
On Open-Source Sustainability ¶
For some, programming is just a job.
For others, programming is a form of artistic expression. For artists, writing open-source software facilitates the top two levels of the Maslow’s hierarchy: self-actualization and esteem. They enjoy writing clean, well-documented code, so anyone using it could feel the same.
Guess who creates (a significant portion of) quality open-source software?

The above certainly applies to me.
I used to maintain a number of Crystal projects, most of which were well-documented and optimally performant. I enjoyed writing documentation and compiling changelogs. I even enjoyed replying to issues, to reveal unexpected use-cases, add new features and squash bugs together.
The greatest project of mine in Crystal was the Onyx Framework, a web framework comprised of a REST server, a database-agnostic SQL ORM and even EDA facilities. I was planning to also implement a GraphQL framework module, and a convenient CLI to ease the development process. Objectively, it is more user-friendly, a better balanced between features and usability, than alternatives.
You can find out more about my journey in programming in the introductory post.
Primitive Needs to Be Ashamed Of ¶
An artist, like any other human, has more needs to satisfy, though. These are safety and psychological needs. In other words, a man gotta pay his bills.
Was I able to pay my rent with open-sourcing?
Nowadays, a senior iOS developer in Russia has a salary of about $4’000 (300’000₽), which is $25 per hour.
At the best times, my salary as an Open-Source engineer was pathetic $70.

I did receive some “tokens of appreciation” from companies a couple of times, but those were not regular, and I could certainly not have a decent living even with them.
You may argue that it was my fault to choose a promising young language with sweet syntax and native performance to invest my time in, but reread this sentence.
Is it easy to pay your bills when you’re a poet?
Poetry is a basic form of art, but only a few, from many talented, poets can make their living doing what they love. Given the same talent level, it takes big luck to become recognized and earn enough to pay rent.
Some poets may come to streets and start reciting their poetry, hoping for a dime donated. Some are more than happy to be hired by a children book publishing company which needs lots of similar poems… As the individualism fades away.
There are several paths for an open-source maintainer:
- To spend their time entirely for free.
- To spend their time entirely for free, but put a link to their pitiful $0.0002/week Liberapay account, which would inevitably infuriate some Rabadash8820. It is also required to always wrap the links with “😂” emojis and constantly feel bad about asking to compensate for your time. The fuck?
- To sell their time as a software consultant and provide direct support for their libraries. These are often sold under the donations sauce and imply the same shameful constraints.
- To choose one of the explicit business model paths, such as open-core, where the product is not an open-source anymore, but a real business with marketing, cold calls, email spam, free trials etc.
Regarding working for free (paths 1 and 2), I love this quote by myself:
Companies rely on those spending their precious time for free in the hope of being hired by those companies. A Saṃsāra’s circle to break.
Compared to poetry, the consultancy path (3) is like giving interviews and explaining your poems to others verse-by-verse. Which is not that bad. Although sometimes you want to spend your time on writing new poems instead of explaining the old ones. Moreover, some precious time has already been put into an old poem and shall be compensated as well. Musicians do not tend to give their already written songs for free, do they?
Regarding an explicit business path (4), I believe that it has the same consequences for software as for poetry or music. An artist starts to think about money more than art, which inevitably leads to worse quality. For example, in the open-core model, a maintainer spends resources on consciously deciding which features are to be deleted from the “open” part, and how to glue them with the paid part.
That being said, are there any other ways to sustain open-source, to make open-sourcing a real job?
Source-On-Demand ¶
For musicians, there are platforms like Spotify, where a listener pays a fixed amount of money regularly, and the platform pays a musician based on how popular they were during the period.
Can it be applied to model open-source sustainability?
One of the problems arising is how to determine the “popularity” of an open-source library. Is that the number of unique downloads (“launches”)? Or maybe some sort of manually-triggered endorsements?
Also, a library may still be useful, but too specific, hence not “popular”. Its maintenance would still require a comparable amount of resources.
The solution may be an algorithm taking into consideration both downloads from, say, unique IP addresses, per month, and manual endorsement actions like claps on Medium. Unfortunately, highly-narrowed, hence unpopular, libraries would still have to look for other sources of funding.
Okay, this looks like a good plan.
But.
In the music world, an artist becoming obsessed with the number of streams rather than with the quality of their music, either loses its popularity or changes trends towards shitty lesser-quality music.

Could the same thing happen in the open-source world?
Yes.
A greedy (or lucky) programmer may create a ton of is-even()-like libraries to be occasionally present as a dependency in a plethora of libraries.
Do they deserve to be rewarded?
Absolutely.
They do create value recognized by dependants, and this shall be properly rewarded.
Does it make the overall situation worse?
Yes, because there eventually is a larger amount of libraries to be aware of and put into dependency lists.
Generally, the more dependencies there are, the worse.
A classic meme
It is clear that value created by a single is-even() library is incomparable to value created by, say, a PostgreSQL driver depending on it.
It would be unfair to award a single “use” of an is-even() library equally to the driver “use”.
How to clearly determine the value then?
I bet on the number of characters in a library’s source code, including those commented (because documentation matters) and in binary files. As a result, it would be more profitable to release big libraries: a user would likely require only the files they need (making an overall library size irrelevant to the compilation time), but the algorithm would still count the total amount of lines of code in a library, regardless of which files are required.
One may argue that such a design would encourage Indian-style coding, with lots of repetitions and other crazy practices. But libraries are typically designed for reuse and continuous maintenance, which means periodically adding new bugs and removing features. This is not a one-time freelance job.
Even if one decides to go sneaky and publish lots of hardly maintainable code, then, well, they will lose the competition, because they will not be able to maintain the code themselves.
Given a choice, a business shall choose a library whichever is maintained and documented better, and whichever compiles and runs faster.
This is not about music taste getting worse, when a user would continue listening to whatever shitty low-effort product is released. It is about clearly defined business needs when compile-time and runtime cost actual money.
Moreover, when a maintainer has a decent user base paying the bills, hence reputation, they (a maintainer) would take on security more seriously.
The model seems win-win to me, at least theoretically. I don’t know if it would work in reality, but I guess it’s worth trying.
Let’s call the model “source-on-demand”.
Impact On A Language ¶
Let’s imagine we’ve solved the open-source sustainability problem by implementing a source-on-demand service for one language ecosystem. What benefits would the language experience?
A real market with healthy competition attracts new library authors and incentivizes the old ones to continue maintenance to stay competitive. That means more libraries in general and less stale issues.
A rich, constantly growing ecosystem attracts new developers, which in turn implement libraries for their own usage, and maybe occasionally publish them.
A healthy competition in the ecosystem frees the language from the backwards compatibility burden. Once it (the language) introduces a breaking change, it’s up to library authors to support the new version. If they decide to drop support for a major language version which is in use, others will likely take the spot.
Wow. Let’s try applying the model to existing languages.
A C++ Implementation ¶
A crazy-looking old man with wild hair steps onto the scene.
Alright kids, now we’re about to build a C++ library hosting service with the source-on-demand model.
Where do we begin?
First of all, we need to look at existing solutions.
Okay, Google, c++ package managers.
Here is the most voted answer on the matter:
There seem to be a few though I’ve never used them.
Well, this is one of the first results a user looking for a C++ package manager stumbles into. Not great, not terrible.
Anyway, the only relevant (and alive) projects I could find are Conan, Buckaroo, Hunter, VCPKG and Pacm. Neither of which is centralized. They all propose to either set up their own package server or download packages directly from sources.
But what about observability? How does one find C++ packages to use in their projects? What I if want, for example, an HTTP server package? My variants are either Googling, GitHubbing, asking on Reddit, lurk through manually maintainted lists of libs… There is definitely a pain to solve!
While working on this article, I’ve tried VCPKG, and it’s pretty damn good in the current stage. It has its problems like inability to select a compiler on Windows or select a compiler in principle, which leads to standard compatibility issues. The latter is more of the loose- C++ -standard issue.
Imagine a shiny new world order with a centralized repository of C++ libraries with good searching features, tags, compatibility information etc.!
Would it actually change anything in current government C++?
I doubt so.
C++ is archaic by itself!
Breaking changes to C++ aren’t possible even if a centralized on-demand library manager was solving the library funding problem. There is no fresh blood in C++, most of the youngsters do not want to bear with poor design the language imposes by itself. The amount of time needed to convince Stroustrup-aged C++ committee members to push breaking changes into the ISO-governed standard… I don’t think it’s feasible by any means.
Old people get older, and C++ software is becoming ancient history. The new generation is not interested in supporting no legacy code unless well-well-paid. What is happening with COBOL now is C++'s inevitable future.
C++ is a pile of poor ad-hoc Postel’s law-governed design decisions and nomenclature, and it is not able to meet modern world requirements anymore.
Viva la revolución!
The speaker is removed by medics while shouting out revolutionary slogans. Another younger-looking gentleman steps onto the scene.
Ahem. As we can see, there is no point in spending time on implementing a C++ package manager, as it would never be standardized (unless you’re a Microsoft), hence widely adopted. C++ itself would become history sooner than it happens. But you, a reader, can try it for yourself. I don’t mind.
Let’s move on.
A Rust Implementation ¶
Implementing such a service for Rust is totally feasible. The (upcoming) Rust Foundation would have total control over crates.io – the de facto standard Rust package hosting platform. All they need to do is to implement the Algorithm.
With such a platform implemented, Rust the language would be free to introduce breaking changes. I’m not sure about whether the concept of editions should remain, though. But anyway.
Even if I, as an individual, manage to implement a crates.io on-demand competitor earlier than the Rust Foundation does, they will inevitably take over, thanking me for the beta-test of the idea. Therefore, there is no motivation for me to spend time on a crates.io competition.
Moreover, I’ve already stated above why I don’t like the Rust language itself. Convincing Rust maintainers to satisfy my complaints in an already stabilized language is more challenging than standardizing a new one.
An Implementation ¶
The same applies for Javascript with recently РЁРёСЂРѕРєР-acquired NPM and my desire for a system programming language rather than… Javascript.
Big guys owning existing centralized package distribution platforms might try solving the Open Source sustainability problem with the source-on-demand model. Until then, no smaller company or individual would dare to implement a competitor, and the suffering continues.
But if I were to implement a new system programming language, I’d then have enough power to experiment with the model. Plus one point to justifying.
On Standardization ¶
Wikipedia does an excellent job of explaining how standardization affects technology:
Increased adoption of a new technology as a result of standardization is important because rival and incompatible approaches competing in the marketplace can slow or even kill the growth of the technology (a state known as market fragmentation). The shift to a modularized architecture as a result of standardization brings increased flexibility, rapid introduction of new products, and the ability to more closely meet individual customer’s needs.
The negative effects of standardization on technology have to do with its tendency to restrict new technology and innovation. Standards shift competition from features to price because the features are defined by the standard. The degree to which this is true depends on the specificity of the standard. Standardization in an area also rules out alternative technologies as options while encouraging others.
By “standardization” Wikipedia means a tedious ISO-grade standardization process spanned by years. What I’m proposing instead is an open specification process driven by the community and businesses. With that, a standard remains flexible, and changes to it are shipped frequently.

The lack of need to maintain backwards compatibility allows multiple major versions of a language standard to peacefully co-exist: more breaking changes are allowed for the language to stay modern.
A language standard presence removes the bus factor when only the ones currently working on the canonical implementation have a deep understanding of the language.
As a result, other implementations may appear, focusing on their own needs. For example, some company may need a compiler for their exotic target.
Take Zig. Andrew has to work on supporting many targets at once. Instead, he could delegate the implementation job to someone else and focus on the language specification. This would speed up the maturing process.


Apart from standardizing the language itself, its ecosystem shall also be standardized, including package management. This would allow competing implementations to remain compatible, giving an end-user more freedom in choosing of right tooling.
If I were working on a language, standardization would matter more than an implementation for me.
Wrapping up ¶

C++, Rust and others have their fatal flaws, but I still want to use a higher-level system programming language.
I’m willing to attempt solving the Open-Source Sustainability problem.
Creating a new language and applying the source-on-demand model to its canonical package hosting platform from the very beginning implies a great chance of prosperity for the language and its ecosystem.
Standardization of the language and its ecosystem implies a greater selection of compatible implementations and tooling for the end-user.
With the language’s ecosystem being adequately funded, the language itself stays flexible, allowing for breaking changes. A flexible language stays modern, forever.
Worths a shot, doesn’t it?
The New Beginnings ¶
Finally, it’s the time to proudly announce another language I’ve come up with, a utopia-grade solution to replace both C++ and Rust once and forever!
So, what are the goals defined for the new language?
-
Developer friendliness:
- Have fundamental design with shared concepts and minimum exclusive cases to keep in mind.
- Infer developer intentions as much as possible, unless ambiguous.
- Guarantee safe, defined behaviour by default, but still provide tools to write and abstract away unsafe code when needed.
- Provide human-friendly object abstractions such as classes, but also contain a number of essential math abstractions to be used when required.
-
Tools for optimal performance. By default, the code written in this language would be suboptimal, but with right tooling it is possible to write perfectly optimized code and abstract it away. With that, a developer would not have to choose another language just because it’s faster. The requirement implies:
-
Access to raw machine instructions, i.e. inline assembly.
-
Pointer arithmetic and alignment.
-
Control over memory ordering.
-
WYSIWYG in terms of clearly understanding what code would compile into.
-
-
Absolute platform agnosticism with the generalization of instructions shared by different instruction sets. The languages should not know anything about operating systems, but common things like integer arithmetics should be abstracted into objects. Modern instructions should be addressed, such as tensors and brain floats.
-
Long-term maintainability of programs written in the language. This includes problems of inheritance, function overloading and so on.
As it turned out, a strong foundation for the language is also needed for success. The foundation goals are:
-
Standardize as much as possible, including:
-
An implementation binary interface and capabilities.
-
Package management.
-
API documentation format.
-
-
Provide proper funding for the ecosystem, including rewarding package authors. This is where the source-on-demand model could be applied.
Are you ready?
…
Drum roll intensifies… 🥁
…
Meet Onyx, the programming language I’ve been working on for a pretty long time now!
Onyx is a general-purpose statically typed programming language suitable both for application and system programming.
Onyx meets all of the goals listed above and even more with the upcoming Onyx Software Foundation. Read more about it in the next Onyx Programming Language article.
In this article, I’ve come to a conclusion that the world needs (yet) another system programming language with a solid foundation and funding of its ecosystem, which would potentially solve all the existing problems.
I have formulated the goals for the new language and its ecosystem and even began working on the implementation, which you can read about more in the next article.